
咨讯


谷歌位于艾奥瓦州的数据中心机房,占地1万多平方米。在全球,谷歌有数十个数据中心。
现在到处都在说"大数据",那么这个"数据"的量到底要多"大",才能叫"大数据"?不就是数据多一些吗,它为什么会这么时髦?
撰文/赵燕枫
大数据,大科学
LSST(大型综合巡天望远镜),是一台还在研制中的巨型望远镜。无论是直径8.36米(将近3层楼高)的巨大主镜,还是囊括近紫外、可见光、红外线(320~1060纳米)的广谱感光元件,还是9.6平方度的超宽广视场(满月的49倍大),以及历史上最大的数码相机(小汽车般大小、重2.8吨),都令人叹为观止。最后,这些零件最后还要被拖到南半球,在智利北部海拔2663米的山顶上重新组装起来,以获得最佳的观测条件。
在工程师们看来,这些都是小意思。那么,什么才是他们最发愁的呢?
你大概想不到,竟然是数据。
LSST的那台超级相机,核心感光元件直径为64厘米(快赶上直径77厘米的标准井盖了),上面分布着1600万个像素,每个像素的动态范围是4字节(byte,1字节等于8比特,本文以下的数据单位均为字节)。在观测时,每秒最多可以产生3吉以上的数据。而相机内的计算机平均每秒要完成2万亿次运算,才能将这些在15秒曝光时间内获取的数据整合为一张32亿像素的照片。每个夜晚,它可以拍下数百张这样的照片,全年则可以拍摄大约20万张。
至此,细节中的魔鬼终于出现了。每个夜晚,LSST能够生成约20~30太的原始数据,每年则能生成1.28拍或者说1280万亿字节数据。项目方估计,为了储存这些数据,初期需要15拍的空间。这相当于15000块常见的1太硬盘的总容量,这些硬盘的总体积大约为50立方米,足够塞满一个小房间。
问题是,如何从这一房间的硬盘中快速查找到所需的某项数据呢?比如,这个天区的某个天体与那个天区的某个天体是不是同类?这类天体还有多少,都在哪里?
对于这样的问题,常规服务器的硬件和软件就只能望洋兴叹了。
在大西洋彼岸的欧洲核子中心(CERN)的LHC(大型强子对撞机)内,分布着约1.5亿个传感器,它们每秒能够传送4000万次数据。当LHC工作时,每秒约产生6亿次粒子碰撞,其中99.999%都会被滤除,只留下约100次碰撞事件供进一步分析。就是这不起眼的0.001%的数据,每年仍可以汇成25拍的数据海洋。为此,人们不得不构建了一个复杂得令人咋舌的LHC计算网格(LHC Computing Grid),它由170个计算设施组成,分布在36个国家。截止到2012年,这个LHC计算网格仍是世界上最大的计算网格。
而LSST和LHC,其实只不过是类似问题的一个缩影。
全球信息存储容量示意图
全球信息存储容量示意图
大数据,大爆炸
说到能够感受到的数据量暴增,可能莫过于我们每天都接触的互联网了。十几年前,网站还以静态页面的展示为主。如今,各种社交网站、电商网站等大量兴起后,情况已经不一样了。
根据中国互联网中心(CNNIC)披露的数据,截止到2013年12月,我国微博用户规模达到了2.81亿。而据新浪官方2012年5月发布的数据,新浪微博用户每天平均发布超过1亿条微博内容。在晚上高峰期,服务器集群每秒要接受100万次以上的响应请求。据中科院院士李国杰在《大数据的研究现状与科学思考》一文中披露,谷歌通过大规模集群和MapReduce软件,每月处理的数据量超过400拍;百度每天大约要处理几十拍数据;淘宝网会员超过3.7亿,在线商品超过8.8亿,每天交易数千万笔,产生约20太数据。
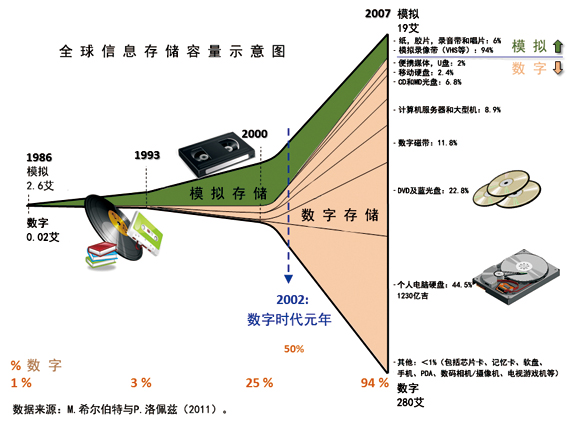
而这,只是全球"数据爆炸"的一个缩影而已。人类记录和储存下的数据,可以分为模拟数据(使用模拟方式记录的数据,包括书刊报纸、信札、录像带、录音带等)和数字数据(使用数字方式记录的数据,包括磁盘、光盘等)两大类。下图所示的,就是最近20多年来,全球信息储存容量的爆炸式发展情况。
在1986年,人类的模拟数据(绿色部分)约有2.6艾,还是新生事物的数字数据(棕色部分)只有0.02艾(20拍),二者比例为130:1。到2002年,二者已经等量,比例变为1:1,被称为"数字时代元年"。到2007年,二者比例已经倒置为1:15。较之1986年,模拟数据增长了6.3倍,达到了19艾;但数字数据更是增长了约14000倍,达到了280艾。事实上,相比于数字数据,模拟数据在全部数据中所占的比重已经越来越低(从1986年的99%一路降到2007年的6%),按照这个趋势,它很快就会变得可以忽略不计。
这个令人目眩的大逆转,仅仅发生在21年间。数据越来越"大"、数字数据越来越膨胀,已经是一个不争的事实。
根据IDC(国际数据公司)在2012年3月发布的《世界大数据技术和服务2012~2015预测》,这个高速扩张的趋势仍在持续。左图是依据这份报告制成的图表。我们可以看到,2012年人类的数字数据约有2.5泽,到2015年时将暴增到8泽。这意味着,在这3年中,平均每年都将新生一份总量相当于2012年人类已有全部数据规模的新数据,而要生成一份总量相当于1986年时全部数据规模的新数据的话,算下来只要不到8个半小时。
从细节上看,左图还叠加了DAZEINFO发布的《下一代网络》中所披露的数据。它告诉我们,这些数字数据是这样分布的(某些数据有统计年代,标注在括号中):博客1.73亿个、邮件107万亿封(2010年)、亚马孙S3云服务器上储存的对象5660亿个(2011年年底)、1.4亿推特用户每天发布的推特3.4亿条、谷歌引擎索引过的页面500亿页、在最大的雅虎Hadoop集群服务器上存储的数据82拍、每分钟都有约60小时长度的视频被上传到Youtube、每月活跃的脸书用户达8.45亿个。当然,它没有标上另外一大块数据来源—在飞速发展的物联网的助力下,各种传感器(包括监视摄像头、RFID读取器、遥感设备、无线传感器等)也在不停顿地生成着新的数据。
按照中国人民大学信息学院孟小峰和慈祥的观点,这些数据可以分为三类,即被动产生的运营系统数据(如销售记录)、主动产生的用户原创数据(如微博内容)和自动产生的感知系统数据(如监控录像)等。从被动、主动到自动,数据量的增幅快速扩大,其中自动产生的数据正是大数据产生的最根本原因。

附件: